到目前為止,我們已經能在 MLflow 裡追蹤模型實驗結果。
但如果要提供服務,僅用 run_id 方式不穩定(容易消失,無版本控制)。
👉 今天我們要:
AnimeRecsysModel)。mlflow models serve 在本地啟動成 REST API。curl 測試推薦結果。請建立 notebooks/day17_serve_with_registry.ipynb,貼上下列程式。
import os
import pandas as pd
import mlflow
import mlflow.pyfunc
from mlflow.tracking import MlflowClient
# 設定 MLflow Tracking
mlflow.set_tracking_uri("http://mlflow:5000")
mlflow.set_experiment("anime-recsys-serve")
# 資料路徑
DATA_DIR = "/usr/mlflow/data"
anime = pd.read_csv(os.path.join(DATA_DIR, "anime_clean.csv"))
ratings_train = pd.read_csv(os.path.join(DATA_DIR, "ratings_train.csv"))
print("Anime:", anime.shape)
print("Train:", ratings_train.shape)
# 訓練 Popular Top-10 模型
top10 = (
ratings_train.groupby("anime_id")["rating"]
.mean()
.reset_index()
.merge(anime[["anime_id", "name"]], on="anime_id")
.sort_values("rating", ascending=False)
.head(10)
)
top10_ids = top10["anime_id"].tolist()
top10_names = top10["name"].tolist()
print("Top 10 Anime:", top10_names)
# 定義 PopularTop10 模型
class PopularTop10(mlflow.pyfunc.PythonModel):
def __init__(self, anime_df, top10_ids):
self.anime = anime_df
self.top10_ids = top10_ids
def predict(self, context, model_input):
# 輸入是動畫名稱,但 PopularTop10 不看輸入,永遠回傳 Top10
return [self.anime[self.anime["anime_id"].isin(self.top10_ids)]["name"].tolist()]
client = MlflowClient()
with mlflow.start_run(run_name="popular-top10-registry") as run:
mlflow.log_param("model_type", "PopularTop10")
# 註冊模型到 Registry
result = mlflow.pyfunc.log_model(
artifact_path="model",
python_model=PopularTop10(anime, top10_ids),
registered_model_name="AnimeRecsysModel"
)
run_id = run.info.run_id
print("Run ID:", run_id)
# 找到剛剛註冊的最新版本
latest_versions = client.get_latest_versions("AnimeRecsysModel")
for v in latest_versions:
print("Version:", v.version, "Stage:", v.current_stage)
new_version = v.version # 取最新的 version
# 把最新版本移到 Staging
client.transition_model_version_stage(
name="AnimeRecsysModel",
version=new_version,
stage="Staging",
archive_existing_versions=True
)
print(f"✅ Model AnimeRecsysModel v{new_version} 已移到 Staging")
現在到 MLflow UI → Models → AnimeRecsysModel → 你會看到這個版本是 Staging。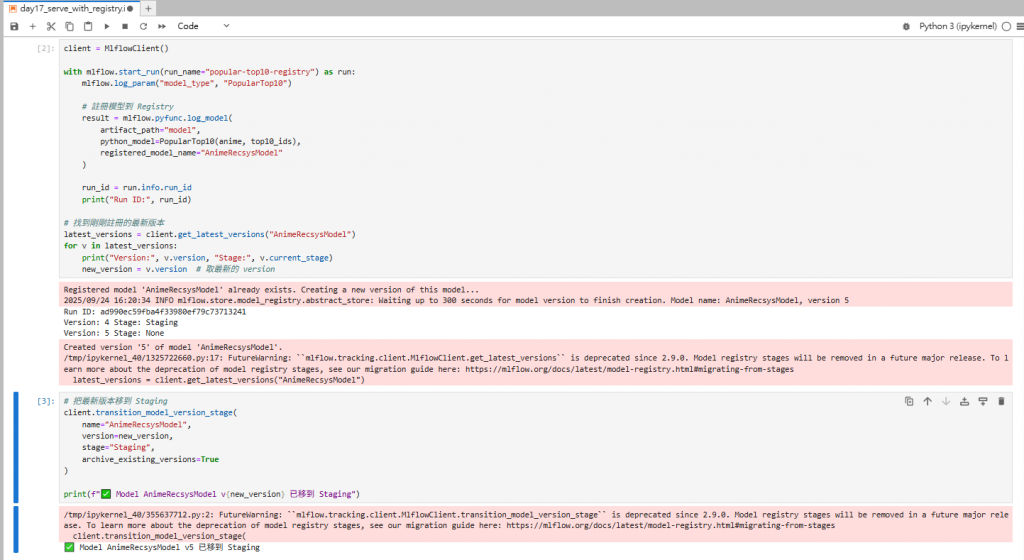
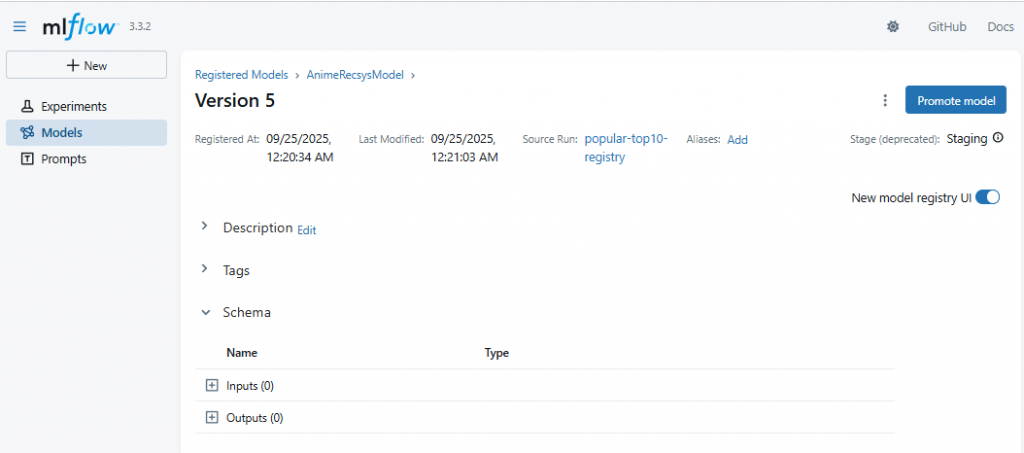
在容器裡執行(注意 Stage):
mlflow models serve -m "models:/AnimeRecsysModel/Staging" -p 5001 --no-conda
這會啟動一個 REST API 在 **http://127.0.0.1:5001**。
開新 terminal,送一個請求:
curl -X POST http://127.0.0.1:5001/invocations \
-H "Content-Type: application/json" \
-d '{
"inputs": [["Naruto"]]
}'
輸出結果會是 Top-10 的動畫清單:

訓練 PopularTop10
│
▼
mlflow.pyfunc.log_model (registered_model_name="AnimeRecsysModel")
│
▼
MLflow Registry
├── v1 → Staging
└── (之後可有 v2, v3…)
│
▼
mlflow models serve (Staging)
│
▼
REST API → POST /invocations
今天我們完成了 訓練 → 註冊模型 → 設定 Stage → Serve 成 API。
和 run_id 相比,Model Registry 的好處是:
企業級推薦系統應該用 Registry + Stage,而不是 run_id。
👉 下一步(Day 18),我們會做一個 模型追蹤與部署總結,整理整個 MLflow 部署管線。


 iThome鐵人賽
iThome鐵人賽